普陀區(qū)智能驗(yàn)證模型熱線
***,選擇特定的優(yōu)化算法并進(jìn)行迭代運(yùn)算,直到參數(shù)的取值可以使校準(zhǔn)圖案的預(yù)測(cè)偏差**小。模型驗(yàn)證模型驗(yàn)證是要檢查校準(zhǔn)后的模型是否可以應(yīng)用于整個(gè)測(cè)試圖案集。由于未被選擇的關(guān)鍵圖案在模型校準(zhǔn)過(guò)程中是不可見,所以要避免過(guò)擬合降低模型的準(zhǔn)確性。在驗(yàn)證過(guò)程中,如果用于模型校準(zhǔn)的關(guān)鍵圖案的預(yù)測(cè)精度不足,則需要修改校準(zhǔn)參數(shù)或參數(shù)的范圍重新進(jìn)行迭代操作。如果關(guān)鍵圖案的精度足夠,就對(duì)測(cè)試圖案集的其余圖案進(jìn)行驗(yàn)證。如果驗(yàn)證偏差在可接受的范圍內(nèi),則可以確定**終的光刻膠模型。否則,需要重新選擇用于校準(zhǔn)的關(guān)鍵圖案并重新進(jìn)行光刻膠模型校準(zhǔn)和驗(yàn)證的循環(huán)。通過(guò)網(wǎng)格搜索、隨機(jī)搜索等方法調(diào)整模型的超參數(shù),找到在驗(yàn)證集上表現(xiàn)參數(shù)組合。普陀區(qū)智能驗(yàn)證模型熱線

三、面臨的挑戰(zhàn)與應(yīng)對(duì)策略數(shù)據(jù)不平衡:當(dāng)數(shù)據(jù)集中各類別的樣本數(shù)量差異很大時(shí),驗(yàn)證模型的準(zhǔn)確性可能會(huì)受到影響。解決方法包括使用重采樣技術(shù)(如過(guò)采樣、欠采樣)或應(yīng)用合成少數(shù)類過(guò)采樣技術(shù)(SMOTE)來(lái)平衡數(shù)據(jù)集。時(shí)間序列數(shù)據(jù)的特殊性:對(duì)于時(shí)間序列數(shù)據(jù),簡(jiǎn)單的隨機(jī)劃分可能導(dǎo)致數(shù)據(jù)泄露,即驗(yàn)證集中包含了訓(xùn)練集中未來(lái)的信息。此時(shí),應(yīng)采用時(shí)間分割法,確保訓(xùn)練集和驗(yàn)證集在時(shí)間線上完全分離。模型解釋性:在追求模型性能的同時(shí),也要考慮模型的解釋性,尤其是在需要向非技術(shù)人員解釋預(yù)測(cè)結(jié)果的場(chǎng)景下。通過(guò)集成學(xué)習(xí)中的bagging、boosting方法或引入可解釋性更強(qiáng)的模型(如決策樹、線性回歸)來(lái)提高模型的可解釋性。普陀區(qū)智能驗(yàn)證模型熱線如果你有特定的模型或數(shù)據(jù)集,可以提供更多信息,我可以給出更具體的建議。

模型驗(yàn)證是機(jī)器學(xué)習(xí)和統(tǒng)計(jì)建模中的一個(gè)重要步驟,旨在評(píng)估模型的性能和可靠性。通過(guò)模型驗(yàn)證,可以確保模型在未見數(shù)據(jù)上的泛化能力。以下是一些常見的模型驗(yàn)證方法和步驟:數(shù)據(jù)劃分:訓(xùn)練集:用于訓(xùn)練模型。驗(yàn)證集:用于調(diào)整模型參數(shù)和選擇模型。測(cè)試集:用于**終評(píng)估模型性能,確保模型的泛化能力。交叉驗(yàn)證:k折交叉驗(yàn)證:將數(shù)據(jù)集分成k個(gè)子集,輪流使用每個(gè)子集作為驗(yàn)證集,其余作為訓(xùn)練集。**終結(jié)果是k次驗(yàn)證的平均性能。留一交叉驗(yàn)證:每次只留一個(gè)樣本作為驗(yàn)證集,其余樣本作為訓(xùn)練集,適用于小數(shù)據(jù)集。
模型檢驗(yàn)是確定模型的正確性、有效性和可信性的研究與測(cè)試過(guò)程。具體是指對(duì)一個(gè)給定的軟件或硬件系統(tǒng)建立模型后,需要對(duì)其進(jìn)行行為上的可信性、動(dòng)態(tài)性能的有效性、實(shí)驗(yàn)數(shù)據(jù)、可測(cè)數(shù)據(jù)的逼近精度、研究自的的可達(dá)性等問(wèn)題的檢驗(yàn),以驗(yàn)證所建立的模型是否能夠真實(shí)反喚實(shí)際系統(tǒng),或者說(shuō)能夠與真實(shí)系統(tǒng)達(dá)到較高精度的性能相關(guān)技術(shù)。 [2]模型檢驗(yàn)在多個(gè)領(lǐng)域都有廣泛的應(yīng)用,它在軟件工程中用于驗(yàn)證軟件系統(tǒng)的正確性和可靠性,在硬件設(shè)計(jì)中確保硬件模型符合設(shè)計(jì)規(guī)范,而在數(shù)據(jù)分析與機(jī)器學(xué)習(xí)領(lǐng)域則評(píng)估模型的擬合效果和泛化能力。此外,在心理學(xué)與社會(huì)科學(xué)領(lǐng)域,模型檢驗(yàn)通過(guò)驗(yàn)證性因子分析等方法檢驗(yàn)量表的結(jié)構(gòu)效度,確保研究工具的可靠性和有效性。將數(shù)據(jù)集分為訓(xùn)練集和測(cè)試集,通常按70%/30%或80%/20%的比例劃分。
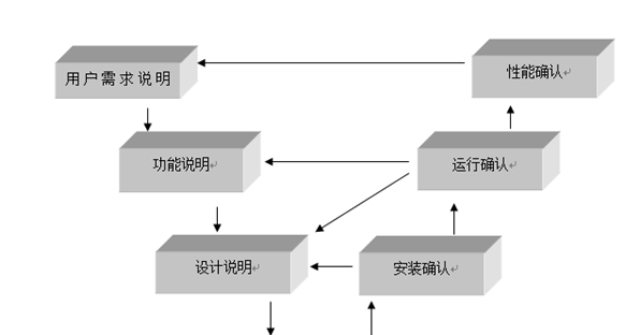
線性相關(guān)分析:線性相關(guān)分析指出兩個(gè)隨機(jī)變量之間的統(tǒng)計(jì)聯(lián)系。兩個(gè)變量地位平等,沒(méi)有因變量和自變量之分。因此相關(guān)系數(shù)不能反映單指標(biāo)與總體之間的因果關(guān)系。線性回歸分析:線性回歸是比線性相關(guān)更復(fù)雜的方法,它在模型中定義了因變量和自變量。但它只能提供變量間的直接效應(yīng)而不能顯示可能存在的間接效應(yīng)。而且會(huì)因?yàn)楣簿€性的原因,導(dǎo)致出現(xiàn)單項(xiàng)指標(biāo)與總體出現(xiàn)負(fù)相關(guān)等無(wú)法解釋的數(shù)據(jù)分析結(jié)果。結(jié)構(gòu)方程模型分析:結(jié)構(gòu)方程模型是一種建立、估計(jì)和檢驗(yàn)因果關(guān)系模型的方法。模型中既包含有可觀測(cè)的顯變量,也可能包含無(wú)法直接觀測(cè)的潛變量。結(jié)構(gòu)方程模型可以替代多重回歸、通徑分析、因子分析、協(xié)方差分析等方法,清晰分析單項(xiàng)指標(biāo)對(duì)總體的作用和單項(xiàng)指標(biāo)間的相互關(guān)系。擬合度分析,類似于模型標(biāo)定,校核觀測(cè)值和預(yù)測(cè)值的吻合程度。虹口區(qū)自動(dòng)驗(yàn)證模型信息中心
將驗(yàn)證和優(yōu)化后的模型部署到實(shí)際應(yīng)用中。普陀區(qū)智能驗(yàn)證模型熱線
在給定的建模樣本中,拿出大部分樣本進(jìn)行建模型,留小部分樣本用剛建立的模型進(jìn)行預(yù)報(bào),并求這小部分樣本的預(yù)報(bào)誤差,記錄它們的平方加和。這個(gè)過(guò)程一直進(jìn)行,直到所有的樣本都被預(yù)報(bào)了一次而且*被預(yù)報(bào)一次。把每個(gè)樣本的預(yù)報(bào)誤差平方加和,稱為PRESS(predicted Error Sum of Squares)。交叉驗(yàn)證的基本思想是把在某種意義下將原始數(shù)據(jù)(dataset)進(jìn)行分組,一部分做為訓(xùn)練集(train set),另一部分做為驗(yàn)證集(validation set or test set),首先用訓(xùn)練集對(duì)分類器進(jìn)行訓(xùn)練,再利用驗(yàn)證集來(lái)測(cè)試訓(xùn)練得到的模型(model),以此來(lái)做為評(píng)價(jià)分類器的性能指標(biāo)。普陀區(qū)智能驗(yàn)證模型熱線
上海優(yōu)服優(yōu)科模型科技有限公司匯集了大量的優(yōu)秀人才,集企業(yè)奇思,創(chuàng)經(jīng)濟(jì)奇跡,一群有夢(mèng)想有朝氣的團(tuán)隊(duì)不斷在前進(jìn)的道路上開創(chuàng)新天地,繪畫新藍(lán)圖,在上海市等地區(qū)的商務(wù)服務(wù)中始終保持良好的信譽(yù),信奉著“爭(zhēng)取每一個(gè)客戶不容易,失去每一個(gè)用戶很簡(jiǎn)單”的理念,市場(chǎng)是企業(yè)的方向,質(zhì)量是企業(yè)的生命,在公司有效方針的領(lǐng)導(dǎo)下,全體上下,團(tuán)結(jié)一致,共同進(jìn)退,**協(xié)力把各方面工作做得更好,努力開創(chuàng)工作的新局面,公司的新高度,未來(lái)上海優(yōu)服優(yōu)科模型科技供應(yīng)和您一起奔向更美好的未來(lái),即使現(xiàn)在有一點(diǎn)小小的成績(jī),也不足以驕傲,過(guò)去的種種都已成為昨日我們只有總結(jié)經(jīng)驗(yàn),才能繼續(xù)上路,讓我們一起點(diǎn)燃新的希望,放飛新的夢(mèng)想!
- 閔行區(qū)自動(dòng)展示車加工熱線 2025-09-22
- 金山區(qū)自動(dòng)汽車設(shè)計(jì)開發(fā)便捷 2025-09-22
- 寶山區(qū)自動(dòng)展示車加工供應(yīng) 2025-09-22
- 黃浦區(qū)口碑好工程樣車試制信息中心 2025-09-22
- 虹口區(qū)智能驗(yàn)證模型便捷 2025-09-22
- 虹口區(qū)銷售工程樣車試制優(yōu)勢(shì) 2025-09-22
- 徐匯區(qū)正規(guī)工程樣車試制大概是 2025-09-22
- 靜安區(qū)銷售汽車設(shè)計(jì)開發(fā)熱線 2025-09-22
- 普陀區(qū)正規(guī)汽車設(shè)計(jì)開發(fā)便捷 2025-09-22
- 靜安區(qū)優(yōu)良驗(yàn)證模型訂制價(jià)格 2025-09-22
- 鎮(zhèn)江B/SFMEA軟件推薦 2025-09-22
- 海南方便長(zhǎng)三角跨境電商人才補(bǔ)貼政策24小時(shí)服務(wù) 2025-09-22
- 內(nèi)蒙古C57原代細(xì)胞實(shí)驗(yàn) 2025-09-22
- 廣東時(shí)尚服飾海外倉(cāng)一件代發(fā) 2025-09-22
- 浦東新區(qū)怎樣企業(yè)拓展便捷 2025-09-22
- 寶山區(qū)推廣桁架搭建優(yōu)勢(shì) 2025-09-22
- 山東升級(jí)版辦公軟件開發(fā)廠家電話 2025-09-22
- 奉賢區(qū)本地房屋檢測(cè)鑒定大概費(fèi)用 2025-09-22
- 黃浦區(qū)如何裝卸搬運(yùn)好處 2025-09-22
- 閔行區(qū)本地展覽服務(wù)哪個(gè)好 2025-09-22